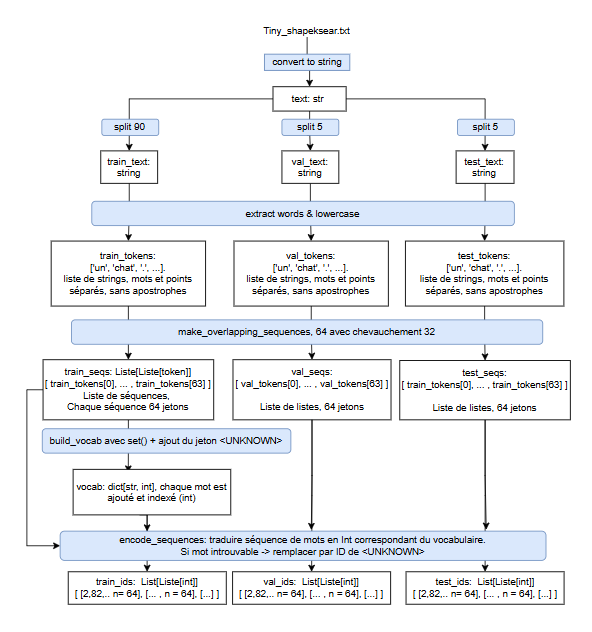
2. Architecture & Models
Embedding Generation
Each token is mapped to a learned 512-dimensional vector, giving the model a continuous space where semantically related words cluster together. Position embeddings are added element-wise to each token vector, making word order explicit to a model that otherwise treats input as a set rather than a sequence. Using learnable rather than fixed sinusoidal positional encodings lets the model adapt position representations to the statistical patterns of the training corpus, at the cost of requiring sufficient training data for those positions to converge.
- Token Embedding: Vocabulary projected into $D=512$ space.
- Position Embedding: Learnable positional vectors are added to indicate word order, as Transformers lack inherent recurrence.
- Result: Input =
Vector(Word) + Vector(Position).
Architecture & Attention
A decoder-only Transformer generates tokens autoregressively by attending over all prior positions through causal multi-head attention, then projecting to a vocabulary distribution. No source sequence exists to encode, so an encoder-decoder stack would add parameters and training complexity without benefit. Eight attention heads partition the 512-dimensional representation into parallel subspaces, letting the model track multiple dependency types simultaneously, at the cost of attention complexity scaling quadratically with sequence length.