1. Context & Objective
This project is a proof of concept (PoC) for an augmented reality company developing an immersive interface where users can write commands and text using only hand gestures. The objective is to determine the feasibility of translating inertial sensor data from a smartwatch into readable letter sequences using deep learning.
Technical Goal
Develop a sequence-to-sequence (Seq2Seq) system capable of translating 2D coordinate trajectories of handwritten words into the correct sequences of letters. Input data comes from preprocessed IMU (inertial measurement unit) data representing continuous one-stroke handwriting traces as sequences of (x, y) coordinates over time.
Project Constraints
- Resource Limitations: The model must operate on a micro-computer with limited memory and computing power
- Parameter Limit: Maximum 10,000 trainable parameters
- Framework: PyTorch (already in use across other company projects)
- Evaluation Metrics: Levenshtein edit distance and a 26-letter confusion matrix
Dataset Characteristics
- Input Format: 2D coordinate sequences (x, y) sampled at regular time intervals, up to several hundred elements per word
- Word Length: English words of 1 to 5 lowercase letters
- Vocabulary: 26 lowercase letters of the alphabet
- Data Split: 70% training / 20% validation / 10% test
Technology Stack

Sample Dataset Entry: Handwritten word "neuron" as 2D coordinate trajectory
2. Architecture & RNN Model
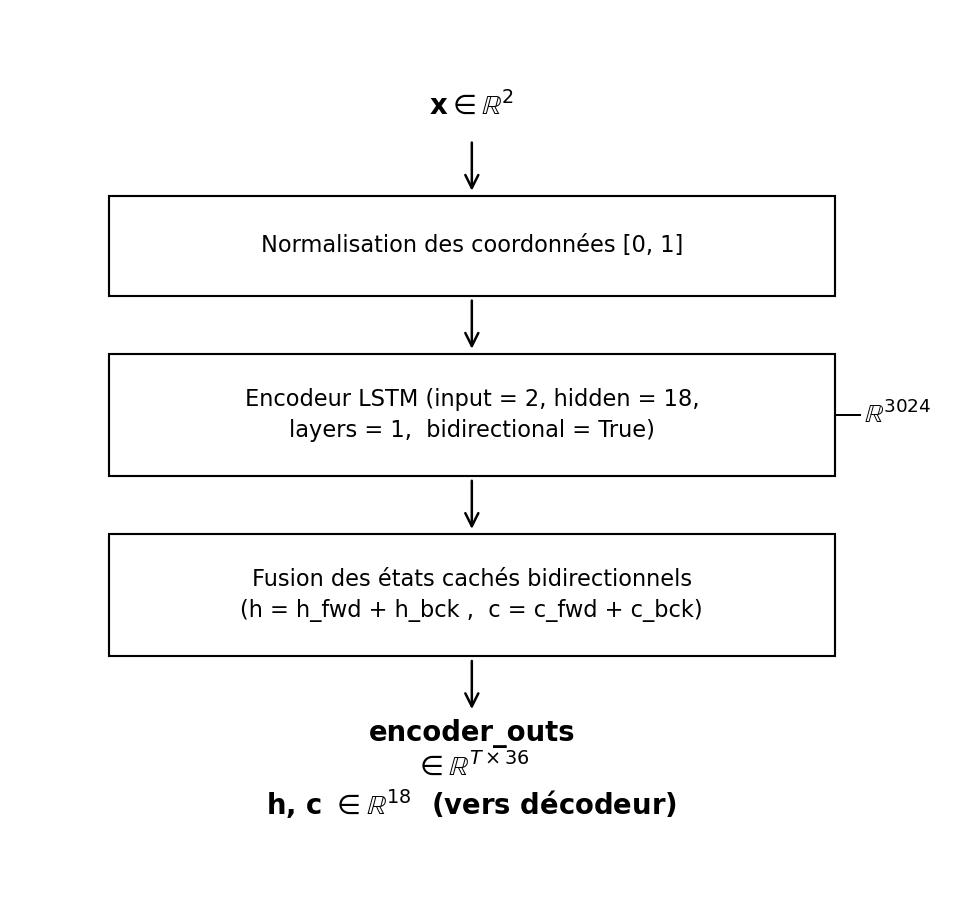
2.1 Bidirectional LSTM Encoder
The encoder processes the full handwriting trajectory and compresses it into rich contextual representations. A bidirectional LSTM reads the 2D coordinate sequence in both forward and backward directions, allowing it to capture shape symmetry and contextual detail that a unidirectional network would miss.
Reading the word both left-to-right and right-to-left lets the model see the full context of the trajectory before encoding it. Because the full sequence is available upfront, using both directions is valid and beneficial.
Design Choices
- Architecture: Bidirectional LSTM
- Input: 2D coordinates (x, y) normalized to [0, 1]
The bidirectional design creates richer trajectory representations: the forward pass captures the natural writing flow while the backward pass captures shape continuations and symmetry, such as mirrored strokes in letters like "o" or "s".
2.2 Unidirectional LSTM Decoder with Embedding
The decoder generates the output word letter by letter, left to right, one step at a time. A unidirectional LSTM is used because the decoder must predict each character without knowing what comes next. A bidirectional decoder would not work here since it would need access to letters that have not been generated yet.
At each decoding step, the decoder receives the embedding vector of the previously predicted letter. The embedding layer maps each character (including special tokens <sos>, <eos>, <pad>) into an 18-dimensional vector space, which helps the model generalize across the 29-symbol vocabulary.
Design Choices
- Architecture: Unidirectional LSTM
- Embedding: Character embedding layer
- No Teacher Forcing: Predicted output used as next-step input, which avoids error compounding
Teacher forcing was deliberately excluded. Using the model's own predictions as inputs (rather than ground-truth letters) prevents errors from compounding and causing repeated letter predictions in the output.
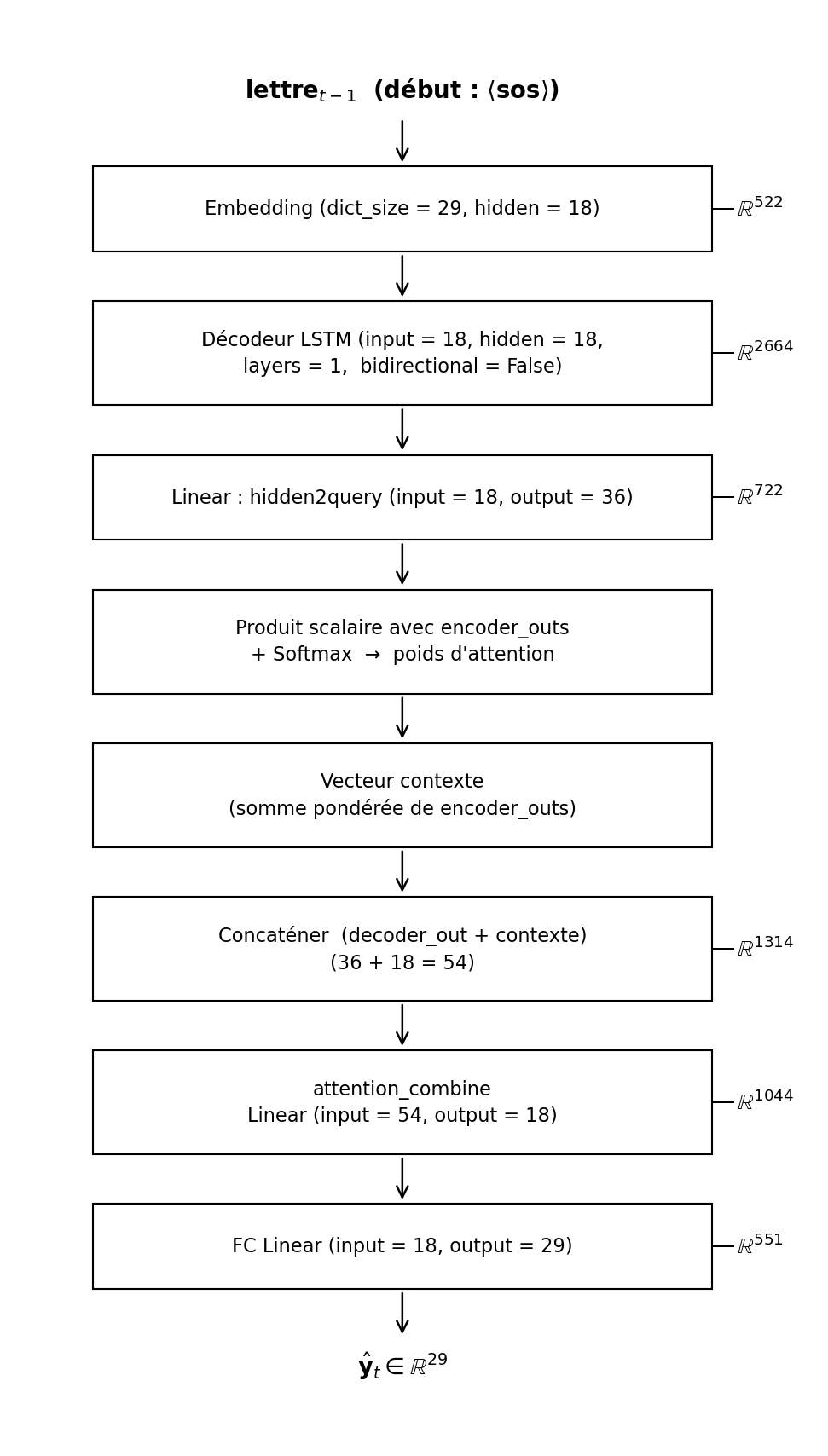
2.3 Attention Mechanism & Full Seq2Seq Model
The attention mechanism is the core innovation of the model, eliminating the encoder-decoder bottleneck by allowing the decoder to selectively focus on specific regions of the handwriting trajectory at each prediction step. For example, the model concentrates on tall vertical strokes when predicting "l" and on loops when predicting "e".
At each decoder step, the decoder's hidden state is compared against all encoder outputs to produce a weighted context vector that highlights the most relevant parts of the trajectory for the current prediction.
Design Choices
- Attention Type: Dot-product (query from decoder hidden state vs. encoder outputs)
- Total Parameters: 9,841 (< 10,000 limit)
Attention replaces the single fixed-length context vector of classic Seq2Seq with a dynamic one recomputed at every decoding step. This is critical for long handwriting sequences, where a single compressed vector would inevitably lose the fine spatial detail needed to distinguish similar-looking letters.
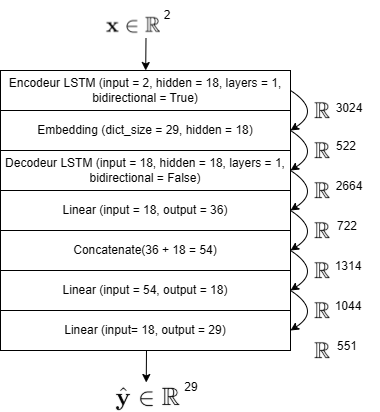
Seq2Seq Architecture with Attention
3. Implementation & Key Decisions
Getting from a random edit distance of ~4 down to below 0.5 on the validation set required careful choices at every step: data preprocessing, architecture selection, and training strategy. Here is what each piece contributed.
Data Pipeline & Preprocessing
Dataset Class
Custom HandwrittenWords Dataset class loads handwritten word data from binary pickle files (data_trainval.p, data_test.p). Split: 70% training / 20% validation / 10% test. Preprocessing applies coordinate normalization between 0 and 1, padding of both coordinate sequences and target letter sequences to uniform batch length, and insertion of special tokens (<sos>, <eos>, <pad>). Bidirectional one-hot conversion is handled via Python dictionaries with a vocabulary of 29 symbols (26 letters + 3 special tokens).
Key Architecture Decisions
Every component of the model required explicit justification within the 10,000-parameter constraint:
Architectural Choices Made
- Chose Bidirectional LSTM encoder + LSTM decoder based on sequence length and parameter constraints
- Bidirectional Encoder: The full trajectory is known before decoding, so reading in both directions gives richer representations
- Unidirectional Decoder: Letters are generated left-to-right and future letters are unknown at decode time, so bidirectional decoding is not possible
- No Teacher Forcing: Prevents error propagation; predicted outputs used as next step inputs throughout training
Critical Constraint: Hidden Dimension Trade-off
The hidden dimension is set to 18, which is the highest value that keeps total parameters below 10,000. The final count is 9,841 (only 159 parameters away from the limit).
Root Cause: Every layer in the model (encoder, embedding, decoder, attention, FC) contributes to the budget. The hidden dimension of 18 was the maximum achievable value that satisfied all constraints simultaneously.
Learning: A small, well-designed model can still perform well. Architecture quality matters more than raw parameter count.
Training Progression
| Training Phase | Train Edit Dist. | Val Edit Dist. | Epoch Range | Status |
|---|---|---|---|---|
| Initial (untrained) | ~4.0 | ~4.0 | 0 | Random predictions |
| Rapid learning phase | <1.0 | <1.0 | 0–50 | Fast alignment discovered |
| Final (300 epochs) | ~0.1 | ~0.4 | 50–300 | Stable, good generalization |
Final Hyperparameters
4. Results & Visuals
4.1 Training & Validation Loss
A final training loss of ~0.05 after 300 epochs, with no upward divergence in validation loss, shows the model is learning genuine representations without overfitting. This is achieved with fewer than 10,000 parameters.
The loss curve drops steeply in the first 50 epochs, then levels off with training loss reaching ~0.05 and validation stabilizing above it. No divergence was observed. The gap between training and validation is normal given the variability in word length and handwriting style across samples.
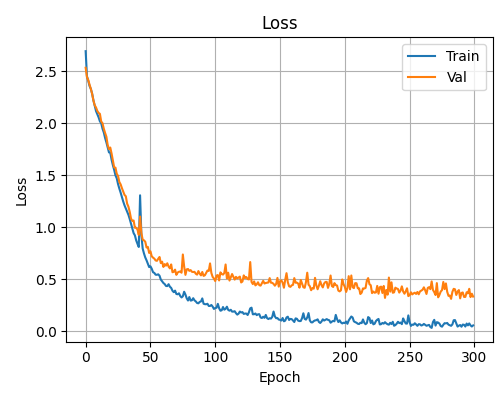
Training and Validation Loss Curves (300 epochs)
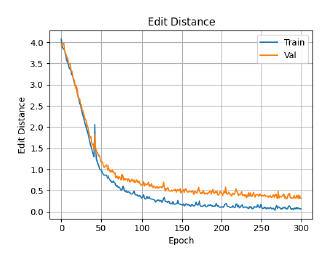
Edit Distance Curves (300 epochs)
The Levenshtein edit distance counts the minimum number of single-character operations (insertions, deletions, or substitutions) needed to transform the predicted sequence into the ground-truth word. A score of 0 is a perfect prediction; a score of 1 means exactly one character differs.
The rapid drop from ~4.0 to below 1.0 in the first 50 epochs shows the model quickly learns to align sequences. The final plateau at ~0.4 for validation indicates the majority of predictions are either fully correct or off by a single character.
4.2 Edit Distance (Levenshtein)
A validation edit distance below 0.5 means most predicted words are either correct or off by one character. This was achieved within the 10,000-parameter limit.
4.3 Confusion Matrix & Translation Examples
A well-populated diagonal in the 26-letter confusion matrix confirms that the model correctly identifies the vast majority of characters. The test example for "islet" shows a perfectly accurate prediction with interpretable attention weights.
The 26-letter confusion matrix on the test set shows a clearly dominant diagonal, indicating strong per-character recognition performance across the alphabet. Frequently occurring letters such as l, e, a, n, i, s achieve the highest accuracy, consistent with their abundance in the training vocabulary. Errors concentrate between visually similar cursive shapes: u and v are frequently confused, as are m and n, which is expected given their resemblance in continuous one-stroke handwriting. Rare letters like q, x, and z have very few training samples and correspondingly higher error rates. Augmenting the dataset with more words containing these characters would directly improve their robustness.
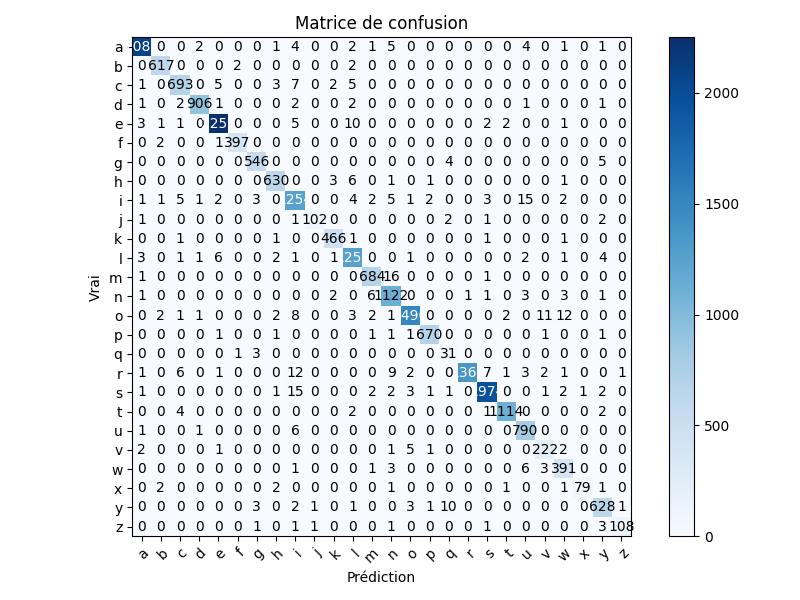
26-Letter Confusion Matrix (Test Set)
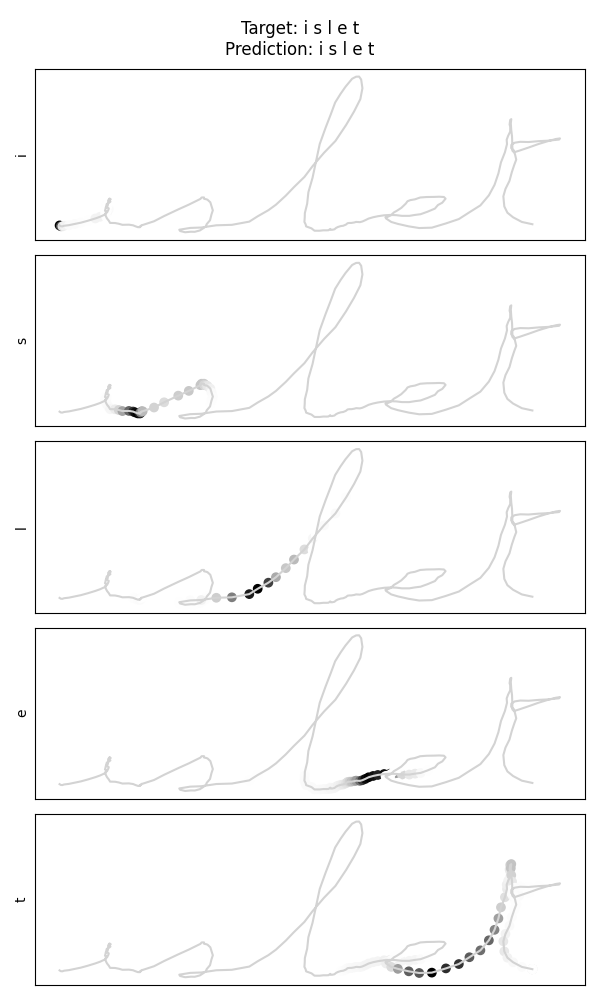
Target: islet → Predicted: islet
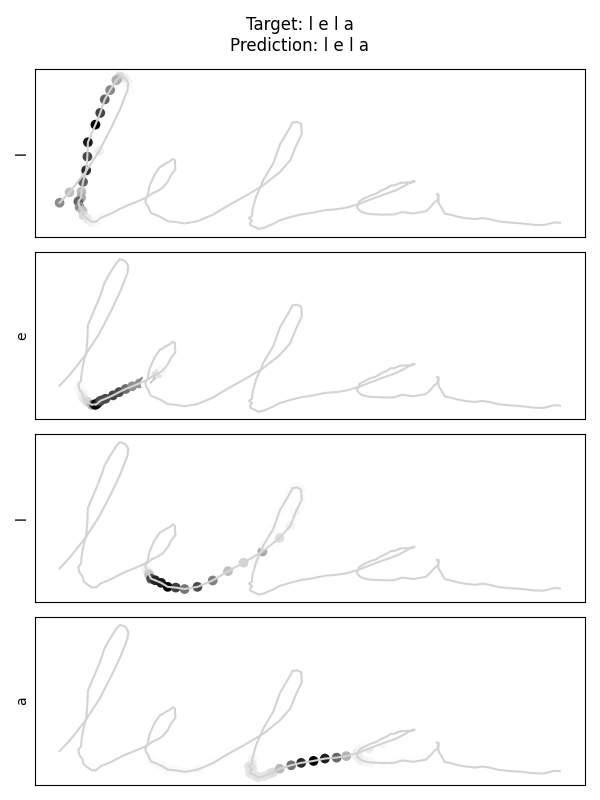
Target: lela → Predicted: lela
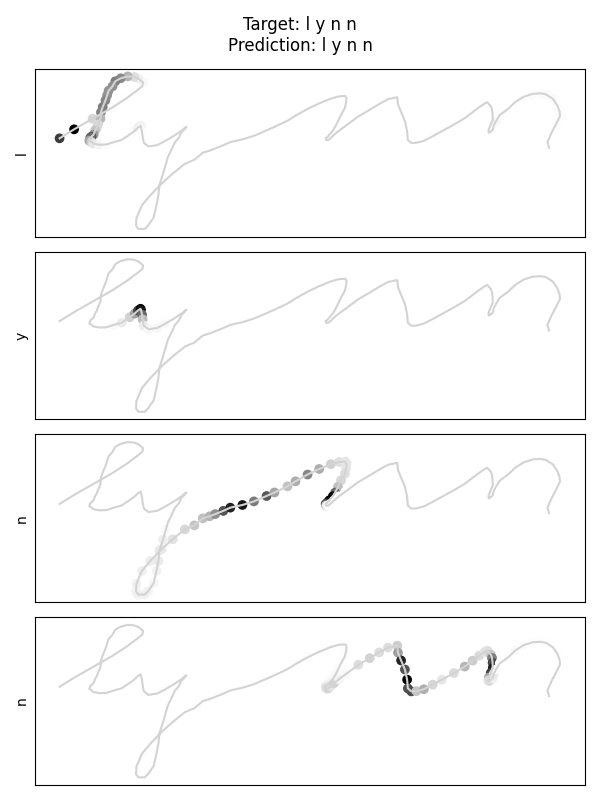
Target: lynn → Predicted: lynn
Reading the attention maps
Attention weights highlight where the model focuses when predicting each letter. The model learned to focus on transition points between letters, where the direction and curvature of the stroke change.
More Prediction Samples

tones
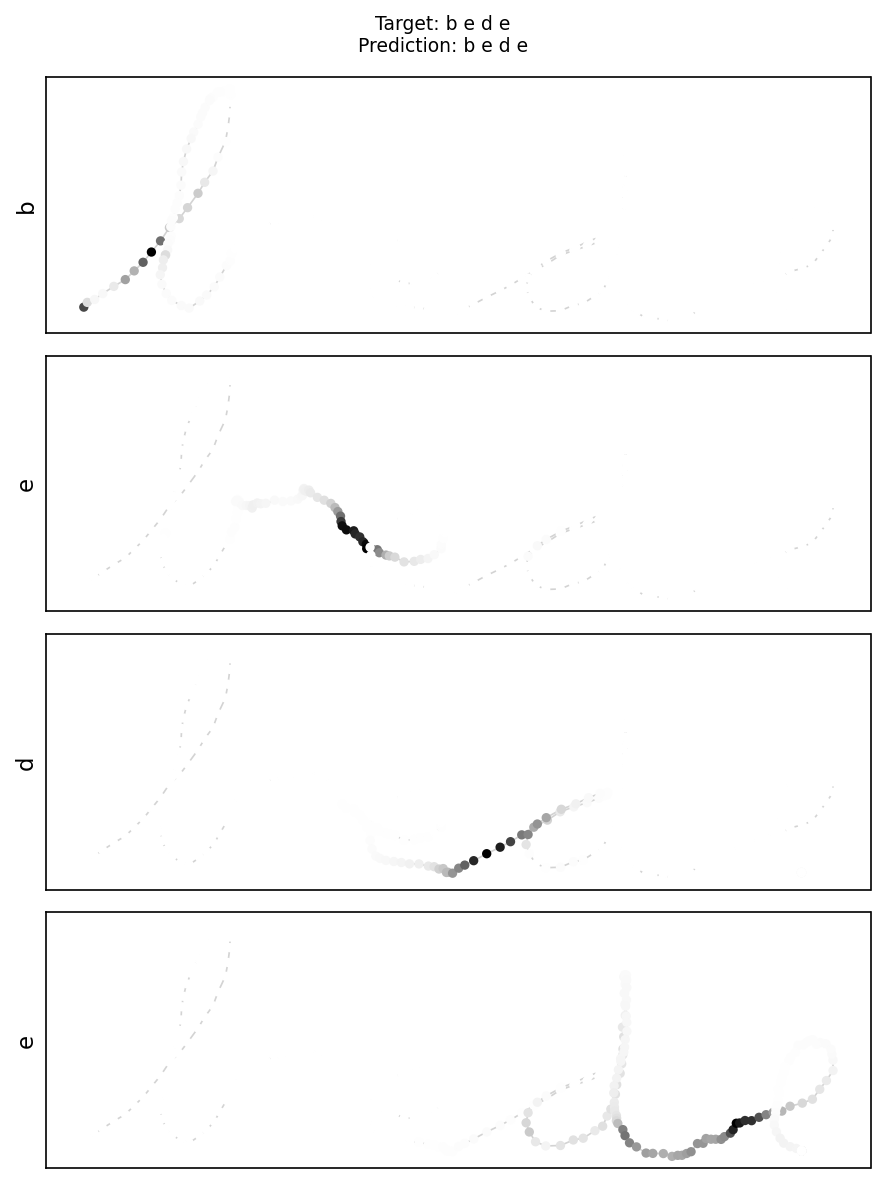
bede
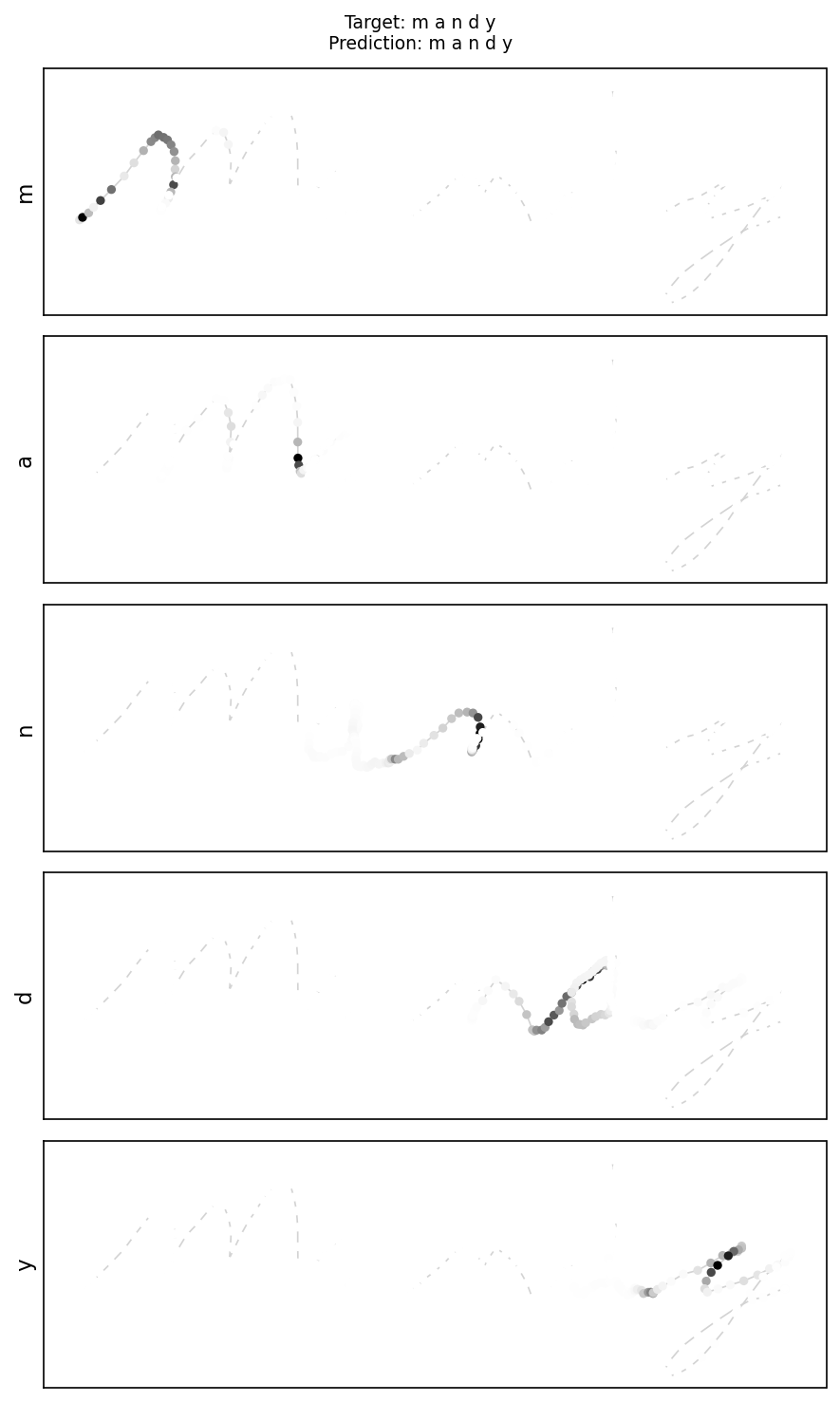
mandy
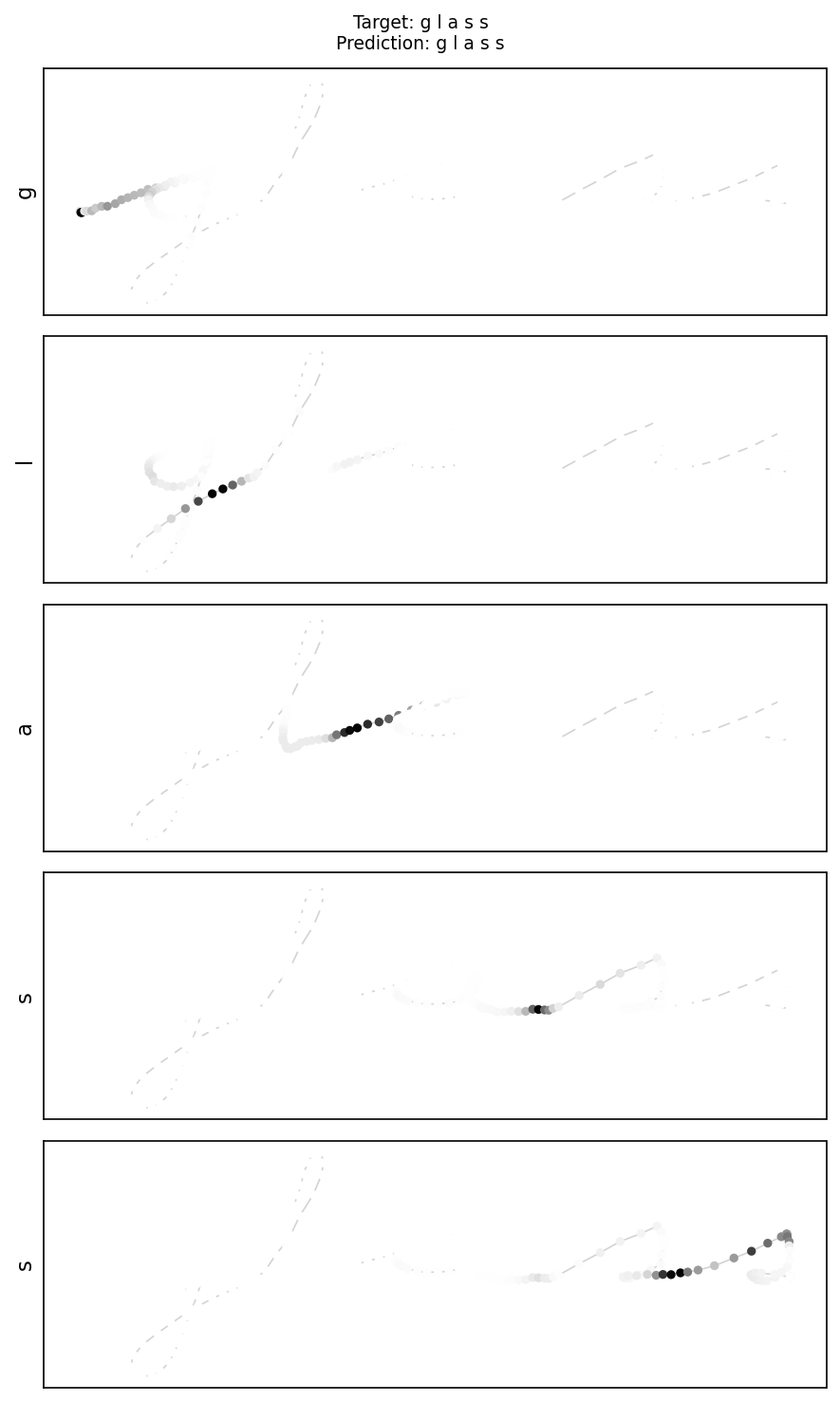
glass
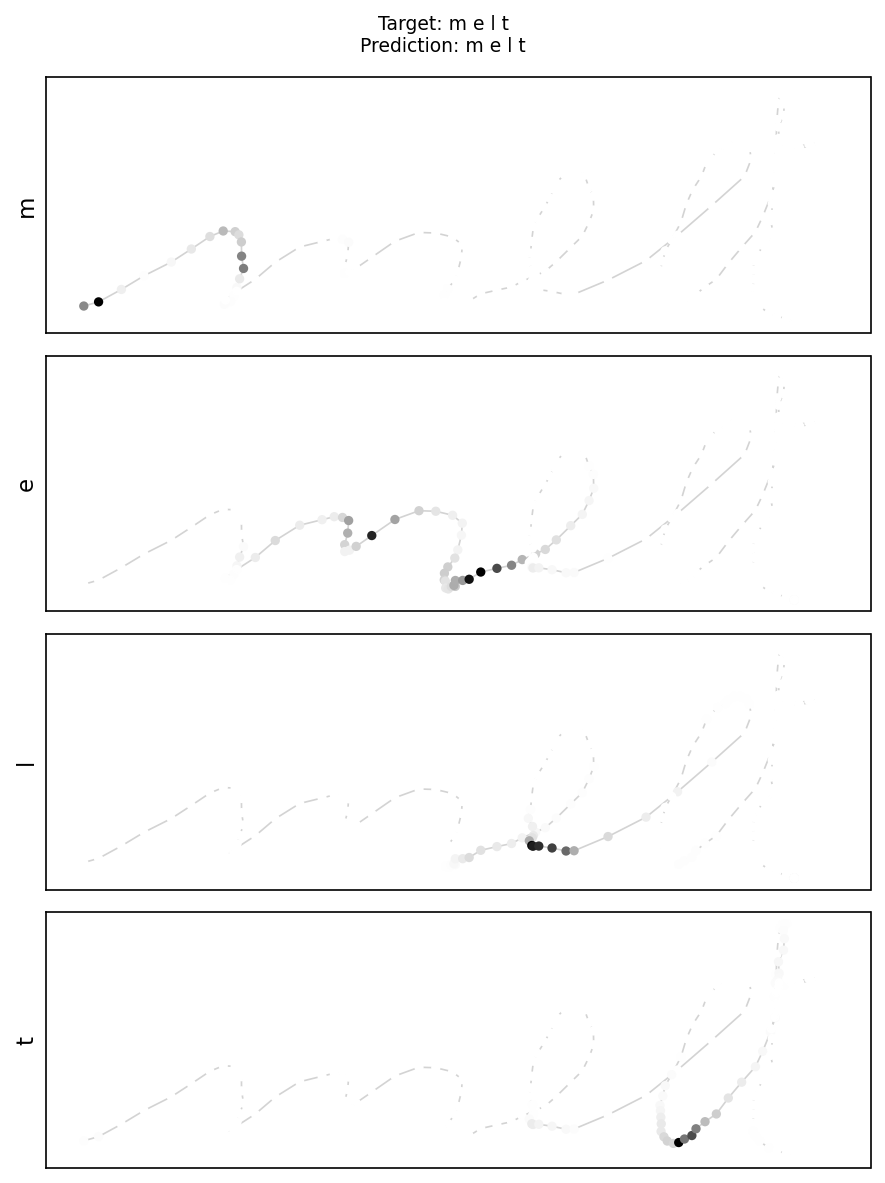
melt

surf
5. Conclusion & Future Perspectives
Project Summary
This project validated the feasibility of handwriting-to-text translation using recurrent neural networks. A Seq2Seq architecture with a bidirectional LSTM encoder, unidirectional LSTM decoder, and dot-product attention mechanism achieves solid translation of 2D handwriting trajectories into letter sequences. The full model uses only 9,841 parameters, within the 10,000 limit.
Key Successes
- Seq2Seq translation with a validation edit distance of ~0.4; most predictions are correct or off by one character
- Strong 26-letter confusion matrix with a clear diagonal, showing good per-letter accuracy across the alphabet
- Parameter constraint respected: 9,841 out of 10,000 parameters used
- Effective attention mechanism: the model learned to focus on letter transition points in the trajectory
- Perfect prediction example on test word "islet" with interpretable attention weights
- Modular, well-documented code across dataset.py, models.py, metrics.py, and main.py
Key Learnings
- Bidirectional encoding creates richer trajectory representations when the full sequence is available at encoding time
- Teacher forcing can cause repeated letter predictions. Using the model's own outputs as inputs is more stable
- Coordinate normalization to [0, 1] is critical: raw coordinates vary too greatly across words of different lengths and writing styles
Future Improvements
- Real IMU Data: Validate on raw smartwatch sensor data to assess domain transfer from preprocessed 2D coordinates
Resources & Links
View Complete Source Code on GitHubAssociated Documents
- Project Statement: Problematique_gro722_guide_etudiant_H25.pdf
- Technical Report: GRO722_cora5428-them0901.pdf
- Source Code: dataset.py, models.py, metrics.py, main.py on GitHub