1. Context & Objective
This project implements an autoencoder neural network dedicated to anomaly detection on the Shuttle dataset. The model learns to reconstruct only normal data in order to identify deviations during the test phase.
The NASA Shuttle dataset contains readings from 9 onboard sensors that monitor the vehicle's operational state during flight. When a sensor develops a fault, its output deviates from the patterns observed under normal conditions. A neural network trained only on normal data learns to accurately reconstruct healthy sensor readings. Any input it cannot reconstruct well becomes a candidate anomaly, turning a manual inspection problem into an automated, always-on detection pipeline.
Technology Stack
2. Architecture & Models
The network adopts a symmetric "hourglass" structure to extract the essential features from the signals.
Architecture Specifications
- Input/Output dimensions: 1×9 → 1×9
- Encoder: Three progressive linear layers (9 → 8 → 7 → 6)
- Activations: ReLU after each linear layer
- Latent Space: Compressed dimension of 6
- Decoder: Mirror structure of the encoder (6 → 7 → 8 → 9)
- Final output: No activation — faithful reconstruction of real values
ReLU layers after each linear layer introduce the non-linearity needed to capture complex relationships in the data. The absence of output activation allows unconstrained reconstruction of continuous values. Mathematically, ReLU computes f(x) = max(0, x), setting any negative activation to zero and passing positive values through unchanged. This forces the network to build sparse, non-negative internal representations at each layer, which reduces redundancy and prevents any single neuron from dominating the learned compression.
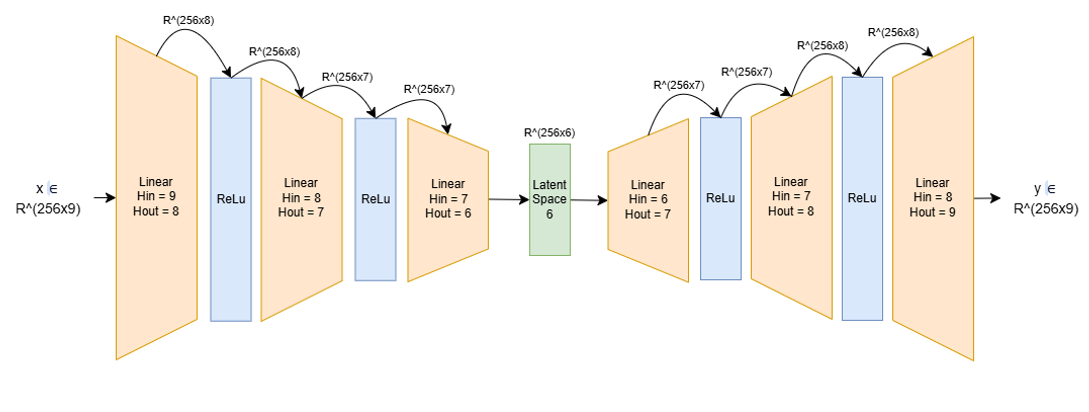
Figure 1: Encoder-Decoder network architecture diagram.
Latent Space Justification (k = 6)
Eigenvalues measure how much variance in the data each component captures. When computed for the Shuttle dataset, 6 values are significantly larger than the remaining 3, meaning 6 directions in the sensor space contain almost all the meaningful signal. Setting k=6 forces the autoencoder to compress the 9 input features into exactly those 6 informative directions, discarding noise while preserving the structure needed to detect deviations.
The choice of k=6 is justified by the following spectral analysis, where the last 6 eigenvalues clearly separate from the first 3:
λ₄ = 6.2564 × 10⁻¹ | λ₅ = 9.8503 × 10⁻¹ | λ₆ = 1.0004
λ₇ = 1.0245 | λ₈ = 1.7436 | λ₉ = 3.6172
3. Implementation & Key Optimizations
Selected Hyperparameters
- Latent Space (k = 6): Based on eigenvalue analysis. Six significant values stand out from the spectrum.
- Learning Rate: 0.0015 — ensures smooth loss stabilization
- Optimizer: Adam — efficient convergence
- Epochs: 80 — convergence plateau reached around epoch 76
- Batch Size: 256, balancing computation throughput and generalization
- Training: Exclusively on normal class data (class 1)
- Loss Function: Mean Squared Error (MSE)
Preprocessing & Normalization
- Preprocessing: Removal of invalid data and label separation to keep only the 9 sensor dimensions
- Normalization: Computed only on valid training data (class 1)
- Test set: Normalized using the training set's mean and standard deviation to prevent anomalies from biasing the scale
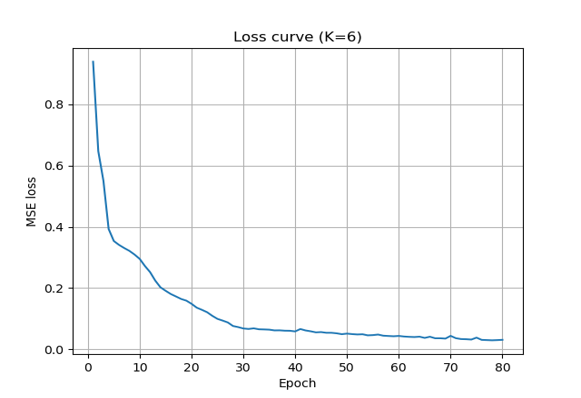
Figure 2: MSE loss evolution (K=6) showing model stabilization.
Convergence by epoch 76 of 80 means the model extracted all learnable structure from the normal class without over-training. A plateau this early in the schedule confirms k=6 is well-matched to the intrinsic dimensionality of the data. Choosing the latent dimension by eigenvalue analysis rather than grid search produced this clean convergence at a fraction of the compute cost.
4. Results
Final classification relies on computing the reconstruction error (MSE). A threshold is determined to separate "normal" from "anomalous".
Threshold Determination
Determination Method
- Objective: Find the ideal trade-off minimizing False Negatives (FN) and False Positives (FP)
- Visual analysis: Loss histograms to identify the separation between the two distributions
- Evaluation: Validated by the F-measure (F1-score) curve as a function of the threshold
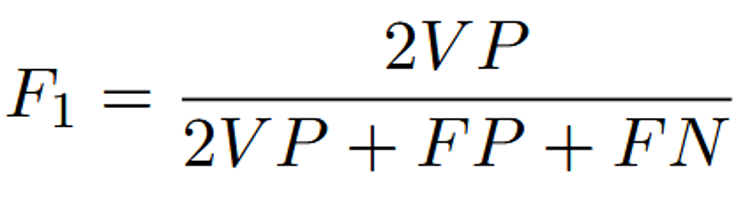
F-Measure formula used for evaluation.
Reconstruction Loss Histograms
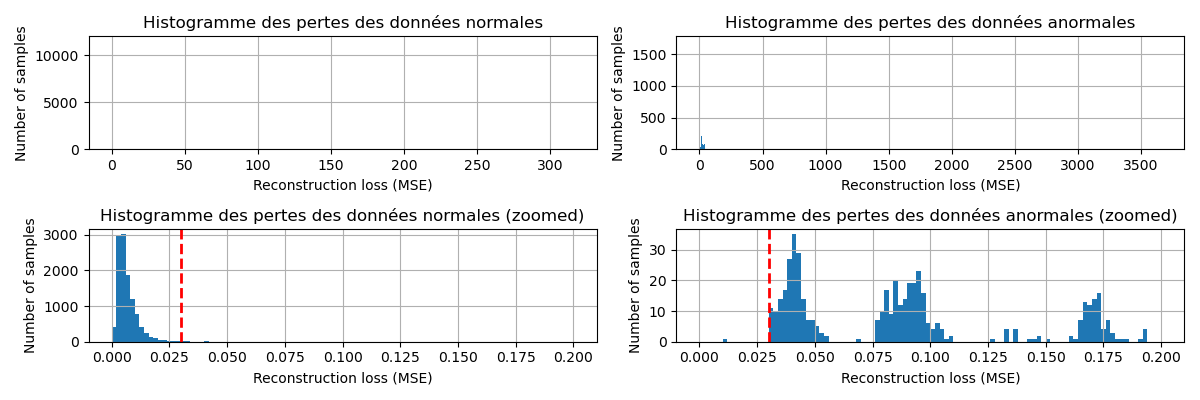
Full distribution of reconstruction errors — normal data vs anomalies.
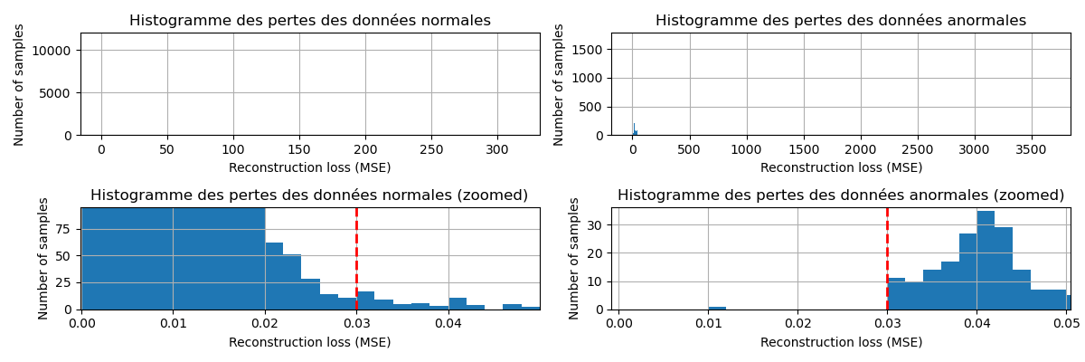
Figure 3: Zoomed view, separation between normal and anomalous distributions.
The clear gap between normal and anomalous reconstruction error distributions means threshold selection carries low risk. Overlapping distributions would force a precision-recall tradeoff with no clean decision boundary. Training exclusively on normal data creates this separation: the network never learns to reconstruct anomalies, so anomalous inputs consistently produce higher errors.
In other words, normal sensor readings cluster below a reconstruction error of roughly 0.03, while anomalous readings consistently fall well above that value. The threshold of 0.03 sits precisely at the gap visible in the zoomed histogram, making it the natural decision boundary where the two distributions are most separated. This value was then used as the reference threshold for the F1-score curve in the section below: the curve peaks at that exact point, confirming that 0.03 simultaneously minimizes missed anomalies and false alarms and is the optimal operating threshold for this model.
F-Measure & Accuracy Curve
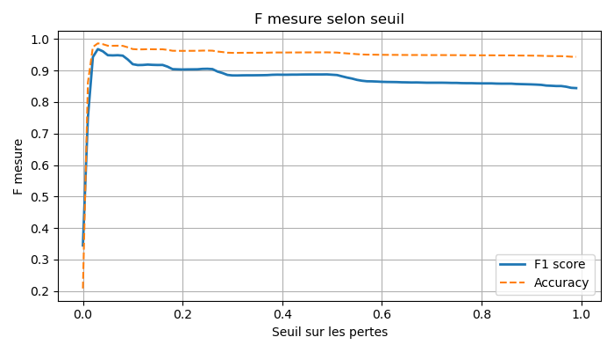
Figure 4: F-measure and Accuracy evolution as a function of the selected threshold.
A sharp F-measure peak at a single threshold value means the optimal cut point is stable and not sensitive to small calibration errors in deployment. A broad or flat peak would signal fragile behavior under distribution shift. The sharpness follows directly from the distributional separation shown in the histograms above.
Final Performance Metrics
An F-score of 0.9912 with 98.62% accuracy means the model misclassifies fewer than 2 samples in 100. For a sensor anomaly detection system, false negatives carry higher operational risk than false alarms, and this result keeps both rates low. Normalizing the test set using training statistics rather than the test distribution prevented anomalies from distorting the normalization scale, which directly contributed to this result.
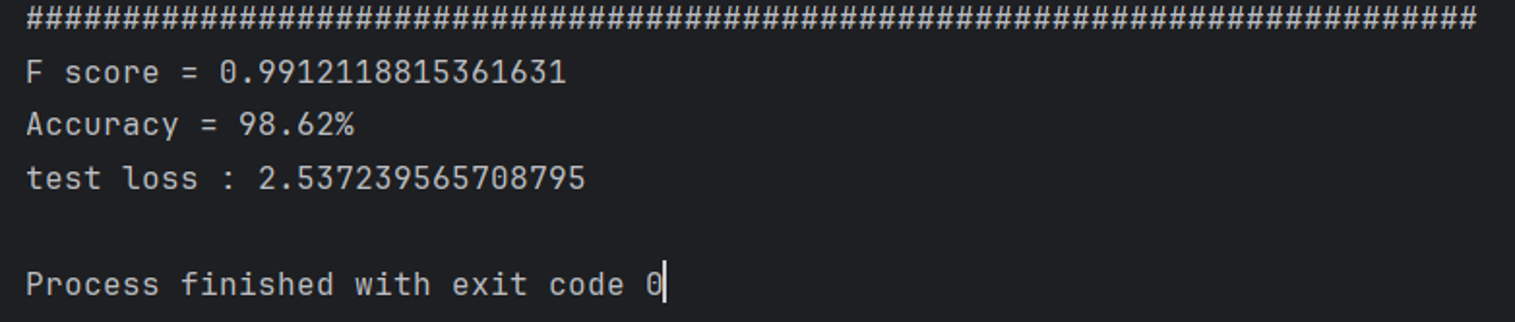
Figure 5: Final anomaly detection results on the Shuttle dataset.
5. Conclusion & Future Perspectives
Project Summary
This project demonstrates that a lightweight autoencoder with a latent space of dimension 6 is sufficient to effectively detect anomalies in the Shuttle dataset. The reconstruction approach trains only on normal data, then thresholds the MSE error to classify. This proves robust and interpretable.
Key Highlights
- F-score of 0.9912, near-perfect for this dataset
- Accuracy of 98.62%, with strong generalization
- Minimalist symmetric architecture: 9 → 6 → 9 with ReLU
- Stable convergence reached by epoch 76 out of 80
- Optimal threshold determined by F-measure analysis, minimizing FP and FN
Future Improvements
- Variational Autoencoder (VAE): Probabilistic latent space modeling for better generalization
- Automatic threshold search: Threshold optimization via cross-validation
- Other datasets: Test robustness on KDD Cup, MNIST-Anomaly, etc.
- LSTM Autoencoder: Leverage the temporal dimension of sensor data
Resources & Links
View Source Code on GitHubAssociated Documents
- Dataset: UCI Shuttle Dataset — 9 sensor features, normal/anomaly classes
- Source Code: Model, training and evaluation scripts on GitHub